Segmentation
between marketing and data science
2017-20-08
last modified: 2022-12-16
1. The role of segmentation in marketing

2. How to segment, in practice?
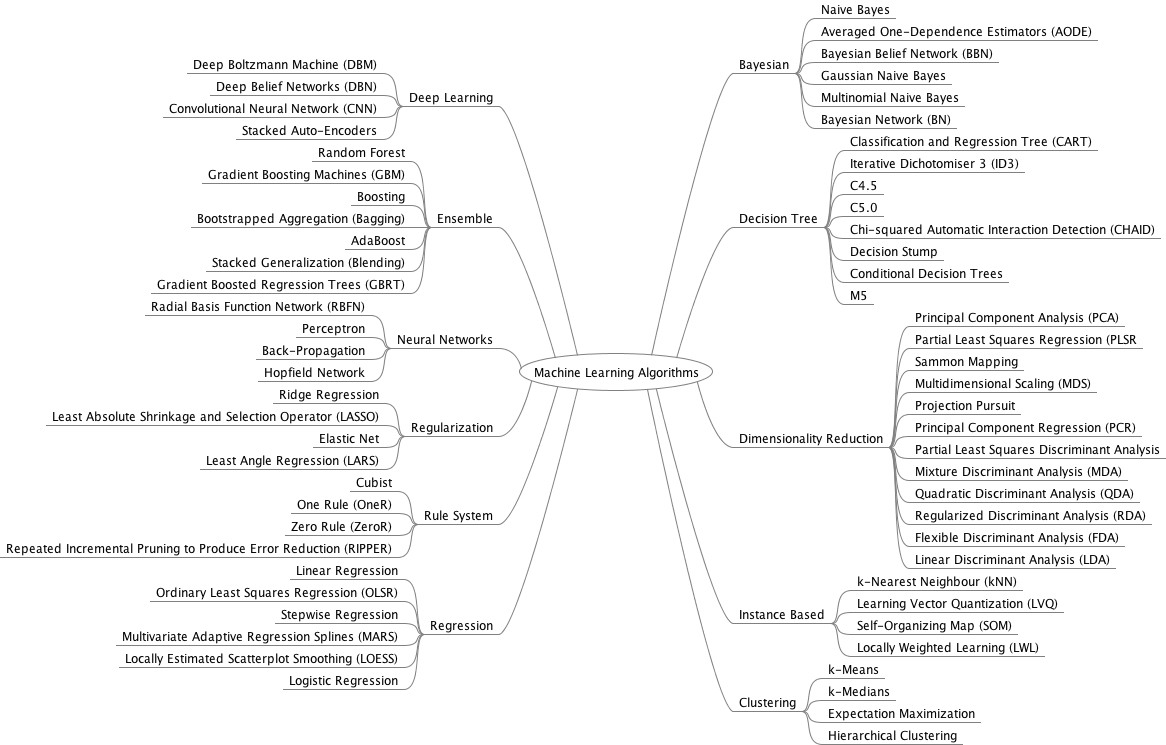

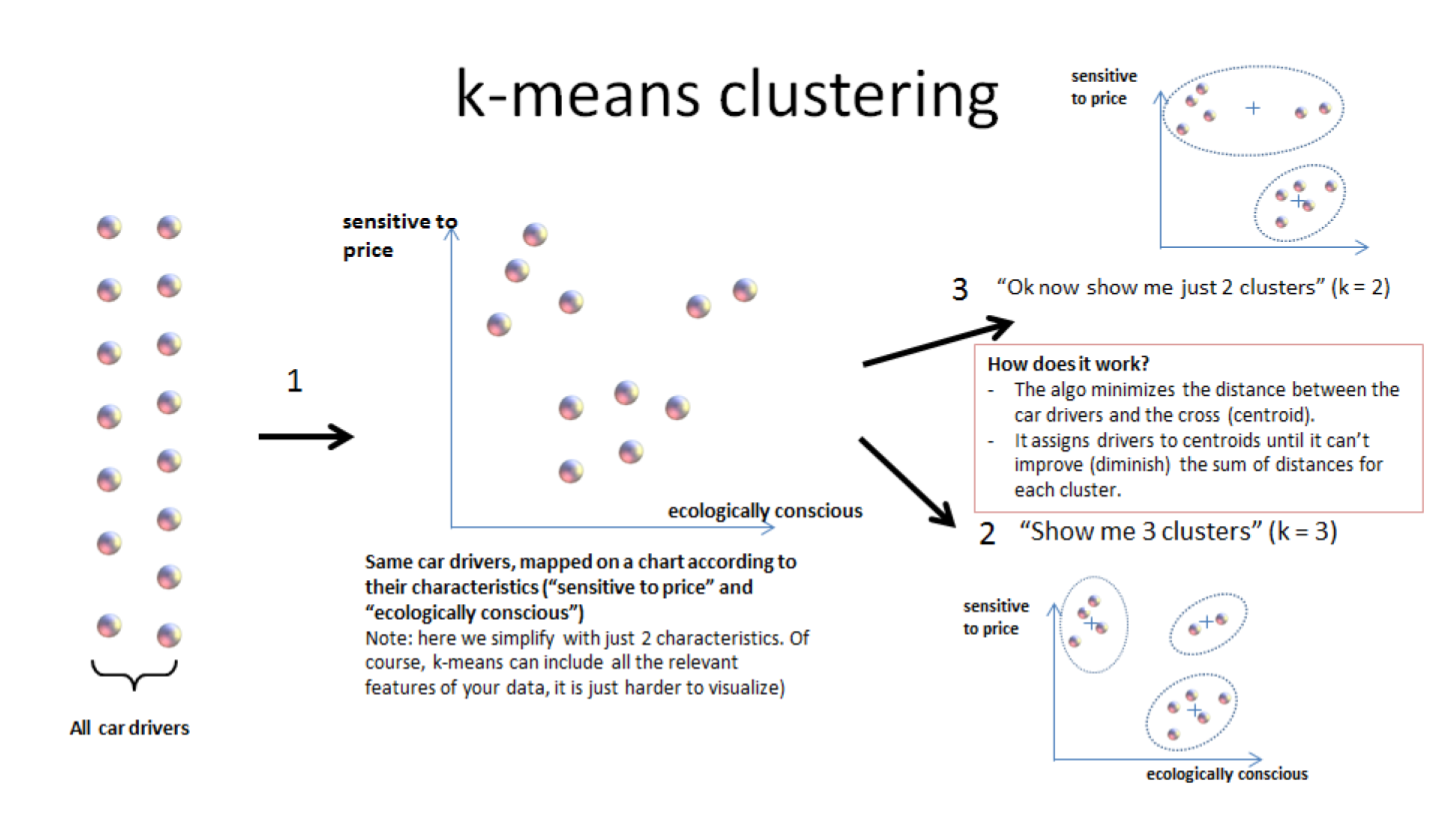
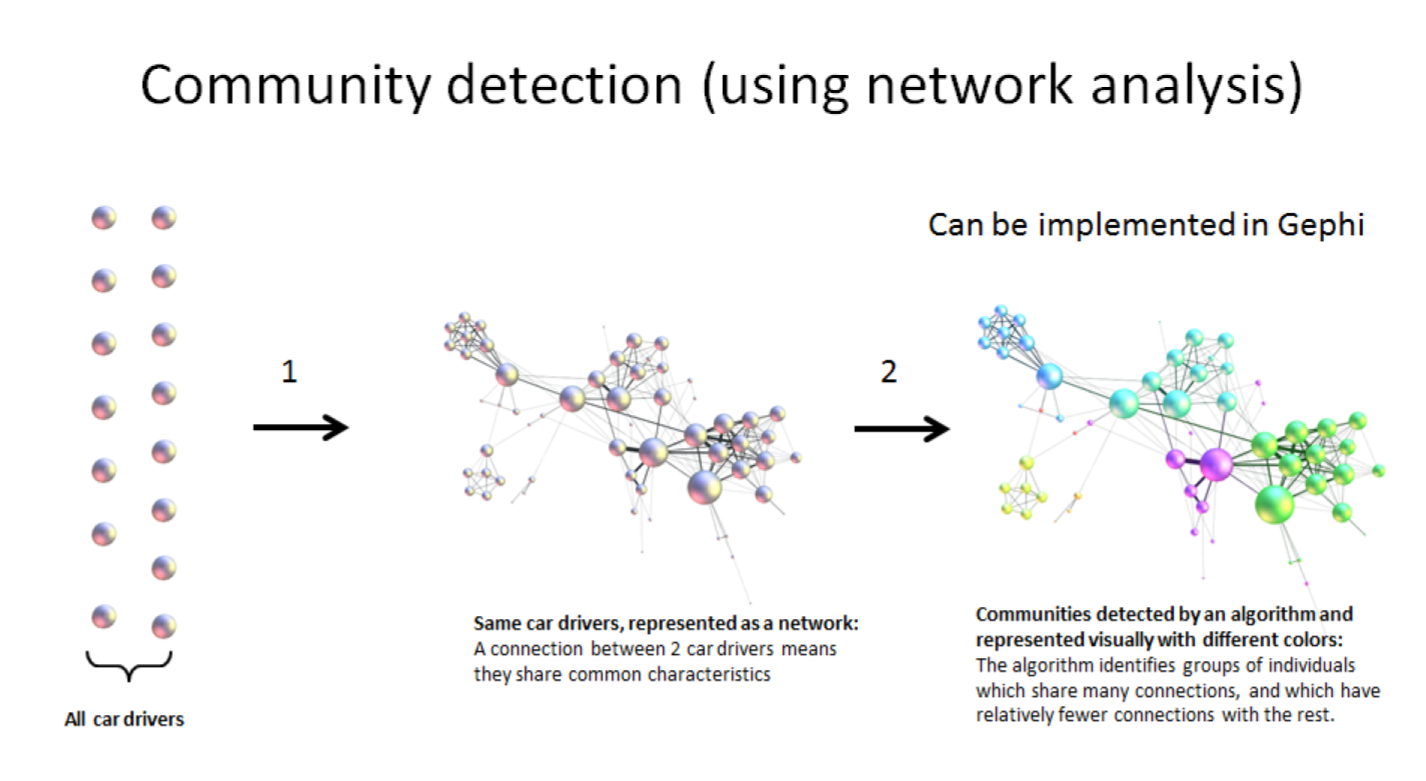
3. Last notes: clustering, useful beyond segmentation in marketing
The end
Find references for this lesson, and other lessons, here.
 This course is made by Clement Levallois.
This course is made by Clement Levallois.
Discover my other courses in data / tech for business: https://www.clementlevallois.net
Or get in touch via Twitter: @seinecle
tps://www.twitter.com/seinecle[@seinecle]
tps://www.twitter.com/seinecle[@seinecle]
tps://www.twitter.com/seinecle[@seinecle]
tps://www.twitter.com/seinecle[@seinecle]
tps://www.twitter.com/seinecle[@seinecle]
tps://www.twitter.com/seinecle[@seinecle]
tps://www.twitter.com/seinecle[@seinecle]
tps://www.twitter.com/seinecle[@seinecle]
tps://www.twitter.com/seinecle[@seinecle]
tps://www.twitter.com/seinecle[@seinecle]
tps://www.twitter.com/seinecle[@seinecle]
tps://www.twitter.com/seinecle[@seinecle]
tps://www.twitter.com/seinecle[@seinecle]